- 48小时新闻排行
- 7天新闻排行

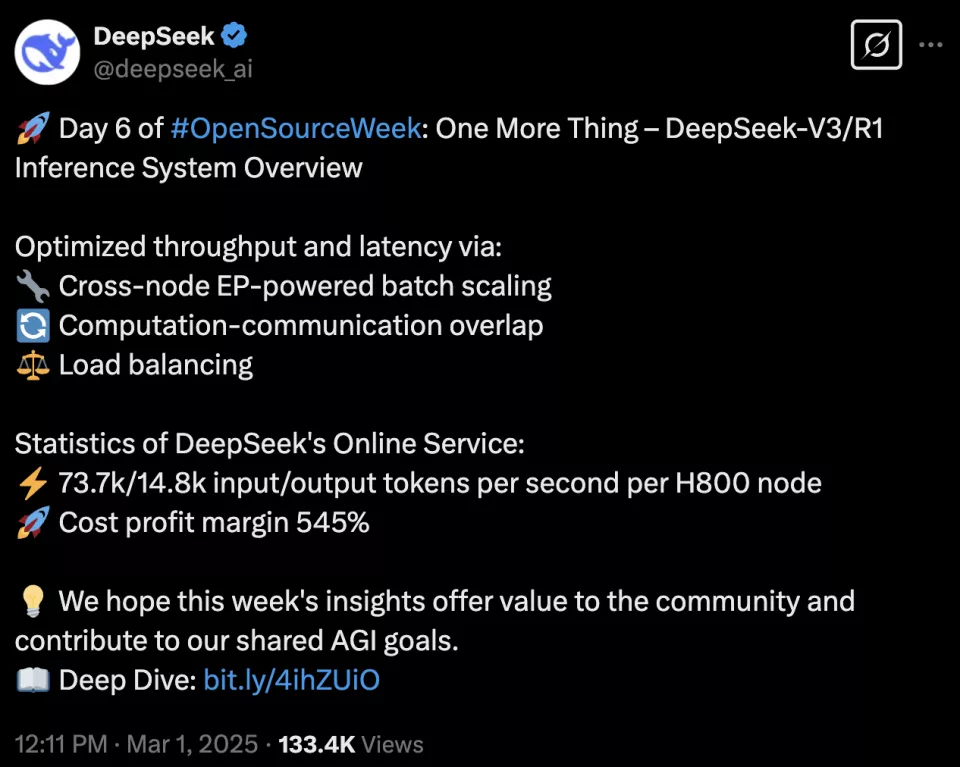
| 智东西3月1日消息,DeepSeek的开源周竟然还有彩蛋!开源第六天,DeepSeek不仅放出了DeepSeek-V3/R1推理系统技术秘籍,还公开了每日成本和理论收入!
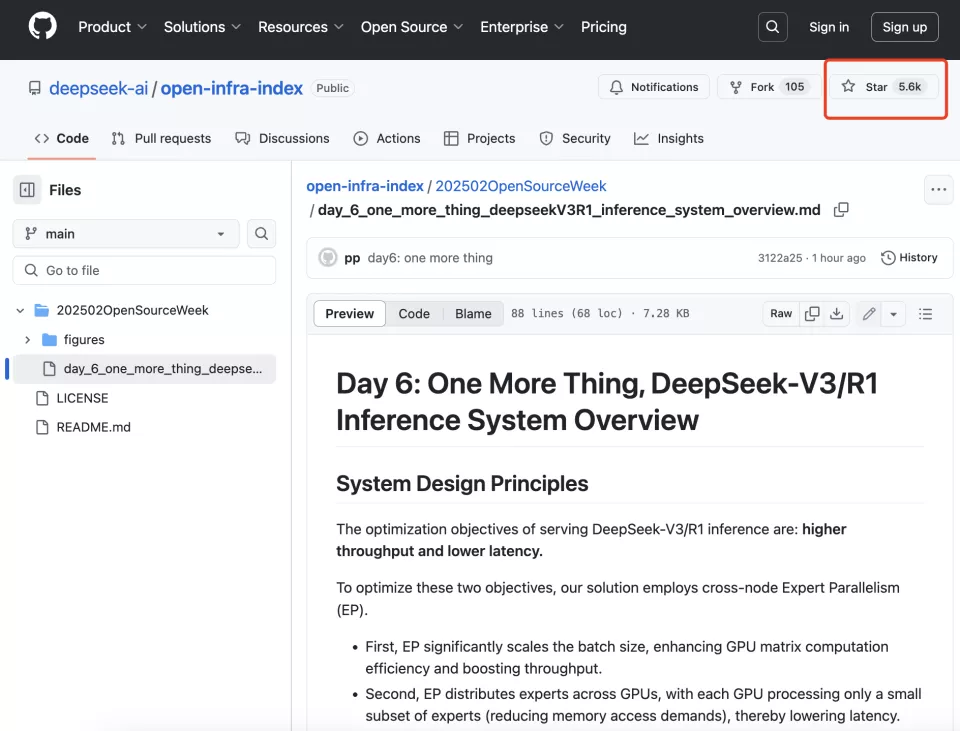
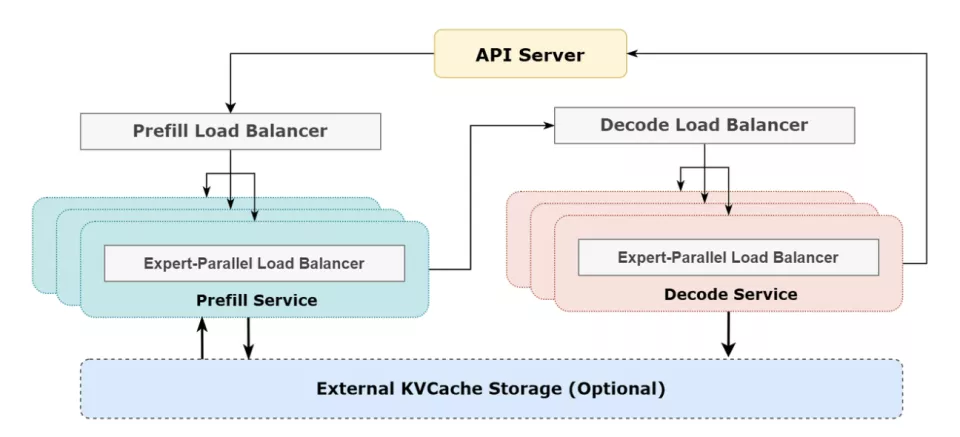
此外,DeepSeek还公开了DeepSeek-V3/R1推理系统概述:为了达到推理更高的吞吐量和更低的延迟,研究人员采用了跨节点的专家咨询(EP),并且利用EP增大batchsize、将通信延迟隐藏在计算之后、执行负载均衡,应对EP的系统复杂性挑战。 发布一小时,GitHub Star数已超过5600。
评论区的网友频频cue OpenAI,直呼“被抢劫”了!
还有网友以OpenAI的定价帮DeepSeek算账:
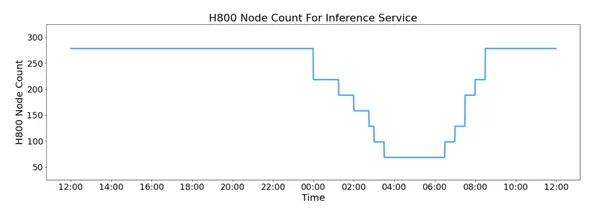
GitHub地址: https://github.com/deepseek-ai/open-infra-index/blob/main/202502OpenSourceWeek/day_6_one_more_thing_deepseekV3R1_inference_system_overview.md 一、每日总成本为87072美元,利润率理论上最高545% DeepSeek V3和R1的所有服务均使用H800GPU,使用和训练一致的精度,即矩阵计算和dispatch传输采用和训练一致的FP8格式,core-attention计算和combine传输采用和训练一致的BF16,最大程度保证了服务效果。 此外,由于白天的高服务负载和晚上的低负载,DeepSeek在白天高峰时段跨所有节点部署推理服务。在低负载的夜间时段减少了推理节点,并将资源分配给研究和训练。 在过去的24小时内(2月27日24点到2月28日24点),V3和R1推理服务的合并峰值节点占用率达到278,平均占用率为226.75个节点(每个节点包含8个H800GPU)。假设一个H800 GPU的租赁成本为每小时2美元,则每日总成本为87072美元。
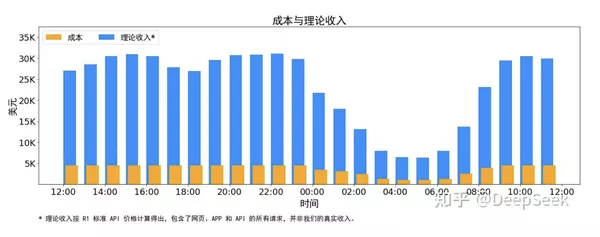
在24小时统计周期内(2月27日24点到2月28日24点),V3和R1: 总输入Token 608B,其中342B Token(56.3%)命中KVCache硬盘缓存。 总输出Token 168B,平均输出速度为每秒20-22tps,每个输出Token的平均kvcache长度为4989个Token。 每个H800节点在prefill期间提供约73.7k token/s输入(包括缓存命中)的平均吞吐量,或在解码期间提供约14.8ktoken/s输出。 以上统计数据包括所有来自web、APP、API的用户请求。 如果所有Token都以DeepSeek-R1的价格计费,每日总收入将为562027美元,成本利润率为545%。 *R1的定价:0.14美元输入Token(缓存命中),0.55美元输入令牌(缓存未命中),2.19美元输出令牌。 然而,DeepSeek的实际收入并没有这么多,其原因是DeepSeek-V3的定价明显低于R1;网页端和应用程序免费,所有只有一部分服务被货币化;夜间折扣在非高峰时段自动适用。
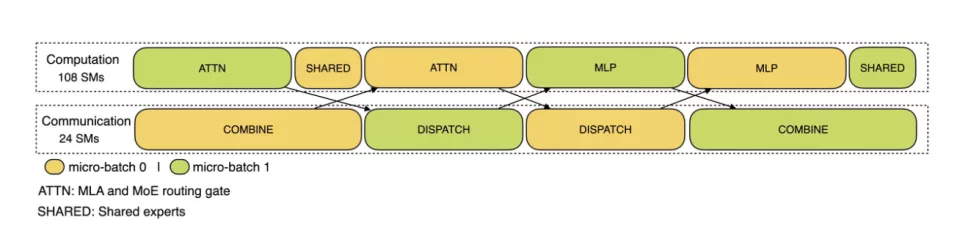
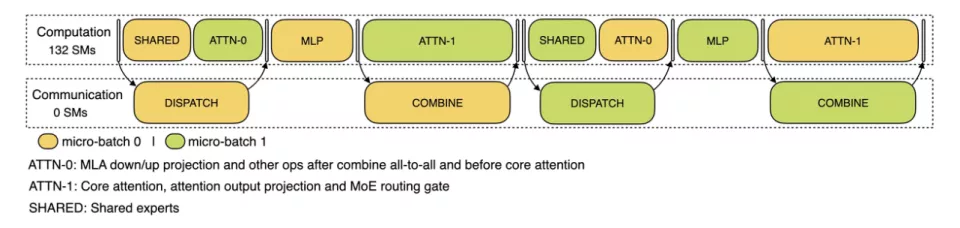
二、EP增加系统复杂性,三大策略应对 DeepSeek的解决方案采用了跨节点的专家并行(EP)。 首先,EP显著扩展了批处理大小,增强了GPU矩阵计算效率并提高了吞吐量;其次,EP将专家分布在不同GPU上,每个GPU只处理专家的一小部分(减少内存访问需求),从而降低延迟。 然而,EP在两个方面增加了系统复杂性:EP引入跨节点的传输,为了优化吞吐,需要设计合适的计算流程使得传输和计算可以同步进行;EP涉及多个节点,因此天然需要DataParallelism(DP),不同的DP之间需要进行负载均衡。 DeepSeek通过三种方式应对了这些挑战: 利用EP增大batch size、将通信延迟隐藏在计算之后、执行负载均衡。 1、大规模跨节点专家并行(EP) 由于DeepSeek-V3/R1的专家数量众多,并且每层256个专家中仅激活其中8个。模型的高度稀疏性决定了其必须采用很大的overallbatch size,才能给每个专家提供足够的expert batchsize,从而实现更大的吞吐、更低的延时。需要大规模跨节点专家并行(Expert Parallelism/EP)。 DeepSeek采用多机多卡间的专家并行策略来达到以下目的: Prefill:路由专家EP32、MLA和共享专家DP32,一个部署单元是4节点,32个冗余路由专家,每张卡9个路由专家和1个共享专家 Decode:路由专家EP144、MLA和共享专家DP144,一个部署单元是18节点,32个冗余路由专家,每张卡2个路由专家和1个共享专家 2、计算-通信重叠 多机多卡的专家并行会引入比较大的通信开销,所以使用了双batch重叠来掩盖通信开销,提高整体吞吐。 对于prefill阶段,两个batch的计算和通信交错进行,一个batch在进行计算的时候可以去掩盖另一个batch的通信开销。
对于decode阶段,不同阶段的执行时间有所差别,所以DeepSeek把attention部分拆成了两个stage,共计5个stage的流水线来实现计算和通信的重叠。
3、实现最佳负载均衡 由于采用了很大规模的并行(包括数据并行和专家并行),如果某个GPU的计算或通信负载过重,将成为性能瓶颈,拖慢整个系统;同时其他GPU因为等待而空转,造成整体利用率下降。因此我们需要尽可能地为每个GPU 分配均衡的计算负载、通信负载。 Prefill LoadBalancer的核心问题:不同数据并行(DP)实例上的请求个数、长度不同,导致core-attention计算量、dispatch发送量也不同。 其优化目标是,各GPU的计算量尽量相同(core-attention计算负载均衡)、输入的token数量也尽量相同(dispatch发送量负载均衡),避免部分GPU处理时间过长。 Decode LoadBalancer的关键问题是,不同数据并行(DP)实例上的请求数量、长度不同,导致core-attention计算量(与KVCache占用量相关)、dispatch发送量不同。 其优化目标是,各GPU的KVCache占用量尽量相同(core-attention计算负载均衡)、请求数量尽量相同(dispatch发送量负载均衡)。 专家并行负载均衡器的核心问题:对于给定MoE模型,存在一些天然的高负载专家(expert),导致不同GPU的专家计算负载不均衡。 其优化目标是,每个GPU上的专家计算量均衡(即最小化所有GPU的dispatch接收量的最大值)。
免责声明:本网转载的文章仅为传播更多信息之目的,本网未独立核实其内容真实性,文章也不代表本网立场。如文章侵犯了你的权利,请联系我们修改或删除。本网提供的内容,包括并不限于财经、房产类信息,仅供参考,不构成投资建议;本网内容,包括并不限于健康、保健信息,亦非专业意见、医疗建议,请另行咨询专业意见。本网联系邮箱:contact@cacnews.ca  |

加拿大 昨天 16:40
印度学生入学德国暴涨370%,楼里印度住户超60%,羽毛球场95%都是他们
国际 昨天 15:43
国际 昨天 15:21
从预言到笑柄:马斯克的Cybertruck摘得美国汽车史最大败笔桂冠
科技 昨天 15:00
加拿大 昨天 14:58
关注获得及时、准确、全方位的新闻消息

 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
10 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
10







